Published On Apr 13, 2024
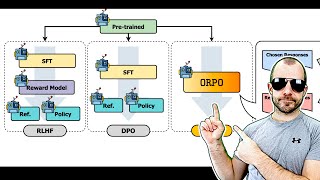
In this video I will explain Direct Preference Optimization (DPO), an alignment technique for language models introduced in the paper "Direct Preference Optimization: Your Language Model is Secretly a Reward Model".
I start by introducing language models and how they are used for text generation. After briefly introducing the topic of AI alignment, I start by reviewing Reinforcement Learning (RL), a topic that is necessary to understand the reward model and its loss function.
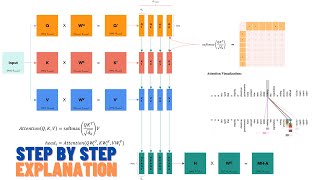
I derive step by step the loss function of the reward model under the Bradley-Terry model of preferences, a derivation that is missing in the DPO paper.
Using the Bradley-Terry model, I build the loss of the DPO algorithm, not only explaining its math derivation, but also giving intuition on how it works.
In the last part, I describe how to use the loss practically, that is, how to calculate the log probabilities using a Transformer model, by showing how it is implemented in the Hugging Face library.
DPO paper: Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S. and Finn, C., 2024. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36. https://arxiv.org/abs/2305.18290
If you're interested in how to derive the optimal solution to the RL constrained optimization problem, I highly recommend the following paper (Appendinx A, equation 36):
Peng XB, Kumar A, Zhang G, Levine S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177. 2019 Oct 1. https://arxiv.org/abs/1910.00177
Slides PDF: https://github.com/hkproj/dpo-notes
Chapters
00:00:00 - Introduction
00:02:10 - Intro to Language Models
00:04:08 - AI Alignment
00:05:11 - Intro to RL
00:08:19 - RL for Language Models
00:10:44 - Reward model
00:13:07 - The Bradley-Terry model
00:21:34 - Optimization Objective
00:29:52 - DPO: deriving its loss
00:41:05 - Computing the log probabilities
00:47:27 - Conclusion