Published On Dec 26, 2023
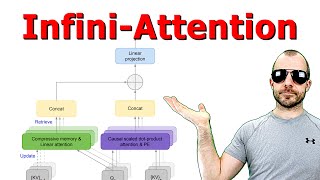
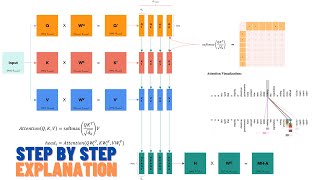
In this video I will be introducing all the innovations in the Mistral 7B and Mixtral 8x7B model: Sliding Window Attention, KV-Cache with Rolling Buffer, Pre-Fill and Chunking, Sparse Mixture of Experts (SMoE); I will also guide you in understanding the most difficult part of the code: Model Sharding and the use of xformers library to compute the attention for multiple prompts packed into a single sequence. In particular I will show the attention computed using BlockDiagonalCausalMask, BlockDiagonalMask and BlockDiagonalCausalWithOffsetPaddedKeysMask.
I will also show you why the Sliding Window Attention allows a token to "attend" other tokens outside the attention window by linking it with the concept of Receptive Field, typical of Convolutional Neural Networks (CNNs). Of course I will prove it mathematically.
When introducing Model Sharding, I will also talk about Pipeline Parallelism, because in the official mistral repository they refer to microbatching.
I release a copy of the Mistral code commented and annotated by me (especially the most difficult parts): https://github.com/hkproj/mistral-src...
Slides PDF and Python Notebooks: https://github.com/hkproj/mistral-llm...
Prerequisite for watching this video: • Attention is all you need (Transforme...
Other material for better understanding Mistral:
Grouped Query Attention, Rotary Positional Encodings, RMS Normalization: • LLaMA explained: KV-Cache, Rotary Pos...
Gradient Accumulation: • Distributed Training with PyTorch: co...
Chapters
00:00:00 - Introduction
00:02:09 - Transformer vs Mistral
00:05:35 - Mistral 7B vs Mistral 8x7B
00:08:25 - Sliding Window Attention
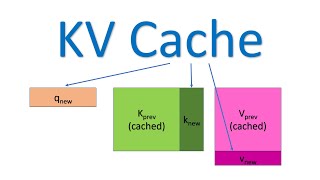
00:33:44 - KV-Cache with Rolling Buffer Cache
00:49:27 - Pre-Fill and Chunking
00:57:00 - Sparse Mixture of Experts (SMoE)
01:04:22 - Model Sharding
01:06:14 - Pipeline Parallelism
01:11:11 - xformers (block attention)
01:24:07 - Conclusion