Published On Jan 31, 2023
Attention is all you need. Welcome to Part 4 of our series on Transformers and GPT, where we dive deep into self-attention and language processing! In this video Lucidate will guide you through the innovations of the transformer architecture, its attention mechanism, and how it has revolutionized natural language processing tasks.
In this video, we cover:
-The introduction of self-attention in transformers
-The limitations of Recurrent Neural Networks (RNNs) and how transformers address them
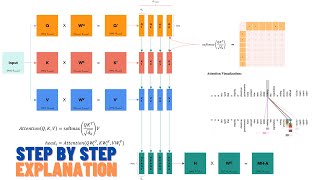
-The role of Query, Key, and Value matrices in attention mechanisms
-The backpropagation process for training transformer models
This video is perfect for anyone interested in understanding the inner workings of transformer language models like ChatGPT, GPT-3 & GPT-4. Don't forget to check out the previous videos in the series to get a complete understanding of the topic.
If you find this video helpful, make sure to like, comment, and subscribe for more informative content on AI, machine learning, and transformers.
Stay connected with us on social media for updates and more exciting content:
LinkedIn: / 86355714
Website: www.lucidate.co.uk
#Transformers #GPT3 #SelfAttention #LanguageProcessing #MachineLearning #AI #Lucidate
Attention is all you need. Transformers like GPT-3 and ChatGPT (as well as BERT and BARD) are incredibly powerful language processing models. They are able to translate, summarise and compose entire articles from prompts. What is the magic, the 'secret-sauce' that gives them these capabilities.
In this video we discuss the transformer architecture and its key innovation, self-attention, which allows the model to selectively choose which parts of the input to pay attention to.
We explain why we need attention and how transformers use three matrices - Query (Q), Key (K) and Value (V) - to calculate attention scores.
We also explains how back propagation is used to update the weights of these matrices.
Finally, we uses a detective analogy to describe how transformers focus on the most relevant information at each step and better handle input sequences of varying lengths.
Stay tuned for the next video where we take a deeper dive into the transformer architecture.
=========================================================================
Link to introductory series on Neural networks:
Lucidate website: https://www.lucidate.co.uk/blog/categ...
YouTube: • Neural Network Primer
Link to intro video on 'Backpropagation':
Lucidate website: https://www.lucidate.co.uk/post/intro...
YouTube: • How neural networks learn - "Backprop...
'Attention is all you need' paper - https://arxiv.org/pdf/1706.03762.pdf
=========================================================================
Transformers are a type of artificial intelligence (AI) used for natural language processing (NLP) tasks, such as translation and summarisation. They were introduced in 2017 by Google researchers, who sought to address the limitations of recurrent neural networks (RNNs), which had traditionally been used for NLP tasks. RNNs had difficulty parallelizing, and tended to suffer from the vanishing/exploding gradient problem, making it difficult to train them with long input sequences.
Transformers address these limitations by using self-attention, a mechanism which allows the model to selectively choose which parts of the input to pay attention to. This makes the model much easier to parallelize and eliminates the vanishing/exploding gradient problem.
Self-attention works by weighting the importance of different parts of the input, allowing the AI to focus on the most relevant information and better handle input sequences of varying lengths. This is accomplished through three matrices: Query (Q), Key (K) and Value (V). The Query matrix can be interpreted as the word for which attention is being calculated, while the Key matrix can be interpreted as the word to which attention is paid. The eigenvalues and eigenvectors of these matrices tend to be similar, and the product of these two matrices gives the attention score.
The Value matrix then rates the relevance of the pairs of words that make up each attention score to the ‘correct’ word that the network is shown during training.
By using self-attention, transformers are able to focus on the most relevant information, helping them to better handle input sequences of varying lengths. This, along with the semantic and positional encodings, is what enables transformers to deliver their impressive performance. In the next video, we will take a deeper dive into the transformer architecture to look at examples of training and inference of transformer language models.
=====================================================================
#ai #artificialintelligence #deeplearning #chatgpt #gpt3 #neuralnetworks #attention #attentionisallyouneed