Published On Jun 14, 2021
Course website: http://bit.ly/DLSP21-web
Playlist: http://bit.ly/DLSP21-YouTube
Speaker: Alfredo Canziani
Chapters
00:00 – Welcome to class
00:15 – Listening to YouTube from the terminal
00:36 – Summarising papers with @Notion
01:45 – Reading papers collaboratively
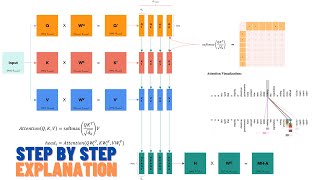
03:15 – Attention! Self / cross, hard / soft
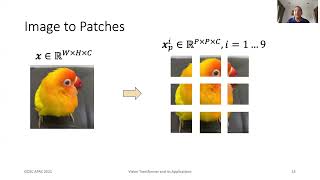
06:44 – Use cases: set encoding!
12:10 – Self-attention
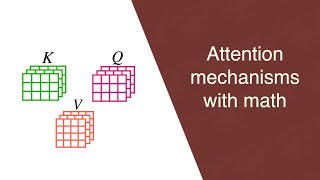
28:45 – Key-value store
29:32 – Queries, keys, and values → self-attention
39:49 – Queries, keys, and values → cross-attention
45:27 – Implementation details
48:11 – The Transformer: an encoder-predictor-decoder architecture
54:59 – The Transformer encoder
56:47 – The Transformer “decoder” (which is an encoder-predictor-decoder module)
1:01:49 – Jupyter Notebook and PyTorch implementation of a Transformer encoder
1:10:51 – Goodbye :)