Published On Nov 30, 2020
ERRATA:
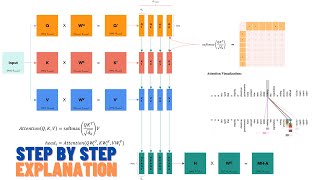
- In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should be different (i).
- In slide 25, the diagram illustrating how multi-head self-attention is computed is a slight departure from how it's usually done (the implementation in the subsequent slide is correct, but these are not quite functionally equivalent). See the slides PDF below for an updates diagram.
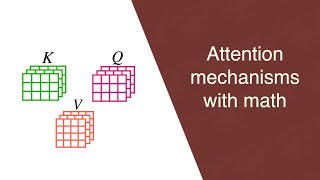
In this video, we discuss the self-attention mechanism. A very simple and powerful sequence-to-sequence layer that is at the heart of transformer architectures.
annotated slides: https://dlvu.github.io/sa
Lecturer: Peter Bloem
show more