Published On Mar 1, 2024
This is the fourteenth lecture of the 11785 Introduction to Deep Learning course at CMU in which we covered the following topics:
- (RNNs are good not just for time-series problems, but also for other nominally MLP problems with sequential structure
- - For example an MLP that adds two binary numbers will require a very large number of neurons and potentially an exponential number of training instances but can be implemented using a tiny RNN that needs only a tiny number of training samples
- - E.g. an MLP for parity check requires a large number of neurons and an exponential number of training instances, but an RNN for the same task is tiny and requires minimal training instances.
- RNNs must ideally be BIBO-stable
- - A sequence of bounded inputs must result in a bounded sequence of outputs
- - More generally, the output must not saturate or blow up
- - In memory terms -- the network must retain memory about key patterns in the input arbitrarily long until is no longer relevant
The stability/instability of the recurrent network is a function of its recurrent hidden layer, so it is sufficient to analyze it.
- Analyzing the recurrent layer we find:
- - For recurrence with linear activation (in the hidden layer), the ability of the network to "remember" an input depends only on the Eigenvalues of the recurrent weight matrix
- - - If the largest Eigenvalue is greater than 1, the output of the network will blow up
- - - If the largest Eigenvalue is less than 1, the output of the network will quickly "die" to 0
- - - Even if the largest Eigenvalues are exactly 1, the network will only "remember" the corresponding Eigenvector, and not the actual input it is supposed to remember
- For nonlinear activations, the recurrent activations will "stabilize" at a value that only depends on the recurrent weights and bias
- - More explicitly, on the Eigenvalues of W
- - Recurrence with Sigmoid activations quickly saturates to their stable value which only depends on weights matrix W and bias b, but not on the input.
- - Recurrence with Tanh activations too quickly saturates to a value that depends only on W and b
- - - But tanh activations take longer to saturate, effectively giving us a greater "memory" time
- - - This is why we generally use tanh activations in recurrent nets
- - Relu activations result in blowing up or "dying" of the recurrent value and do not represent the input
- For deep networks, we also see the problem of vanishing and exploding gradients during training
- - Backpropagation is a chain of multiplications of Jacobians and Weight matrices
- - Very few singular values are greater than 1, most if not all of them will be less than 1
- - As a result, for deep networks, gradients will shrink during backpropagation and eventually vanish
- - - Except for a very small number of directions (with singular values greater than 1) where they will blow up
- - Recurrent networks are very deep networks that also have the same problems in training
- Recurrent networks thus have two problems: they have poor "memory" and derivatives do not travel well in the backward pass. Both problems arise because forward/backward signals are distorted or diminished by the recurrent weights and activations.
- The ideal behavior for a recurrent network is where information stored in their recurrent "memory" is retained arbitrarily long until they are no longer required
"released" by patterns detected in the input
- Such behavior can be obtained by eliminating the recurrent weights and activations in the network
- Memory contents must be modified through explicit pattern detectors that analyze the input
- The actual recurrent state is obtained by branching the memory of and separately applying an activation to it
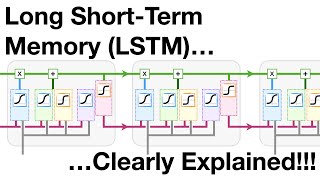
- This architecture gives us the "Long Short-Term Memory" (LSTM) neurons
- The overall cell takes in 3 values -- an input, a CEC value, and a hidden state -- and outputs 2 values: a CEC value and a hidden state.
- The LSTM network is composed similarly to RNNs, with LSTM cells replacing the recurrent units of a conventional RNN.
- They can be incorporated into both one-sided and bi-directional networks.
- Backpropagation through an LSTM can be complex and is most conveniently performed through code: by computing derivatives for each of the forward operations in the cell, in reverse order.
- Gated Recurrent Units (GRUs) simplify LSTM cells by eliminating some computations
- A single gate replaces the input and forgets gates
- The cell only computes the raw CEC value, instead of both the CEC and hidden state. The CEC value is transformed through an activation, before using it for input pattern detection.